
ClipFlow
영상 무음 자동 제거
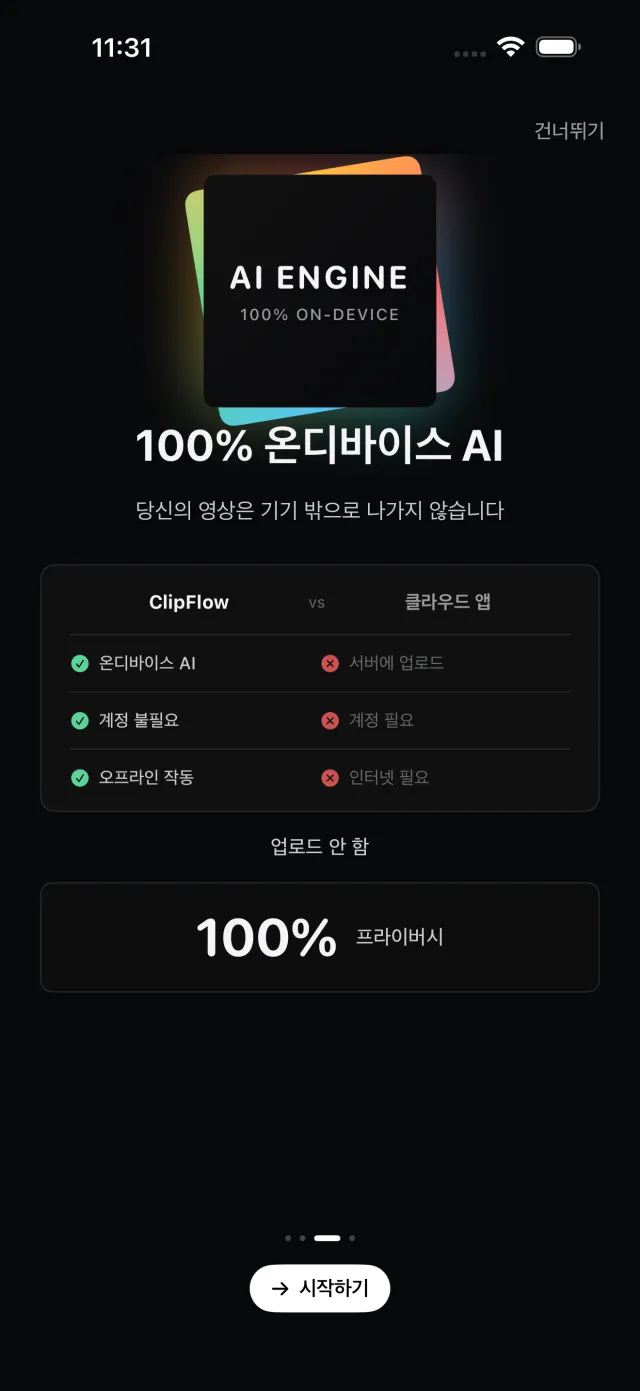
ClipFlow는 영상의 무음 구간과 군더더기 말을 자동으로 찾아 잘라내고, 자막·자동 리프레임·플랫폼별 내보내기까지 한 흐름으로 처리하는 iOS 영상 편집 앱입니다. 음성 인식과 영상 처리가 모두 온디바이스로 동작해 서버 업로드 없이 프라이버시를 지킵니다. Clean Architecture(Domain·Data·Features·Core)와 Swift 6 complete strict concurrency 위에서 무거운 미디어 처리를 actor로 격리한 처리 파이프라인으로 구성되었습니다.
유튜버·숏폼 크리에이터에게 무음 컷과 '음·어' 같은 군더더기 말 제거는 영상 한 편에 가장 많은 시간이 드는 단순 반복 작업입니다. ClipFlow는 이 과정을 Accelerate(vDSP) 기반 온디바이스 오디오 분석과 Speech 프레임워크 음성 인식으로 자동화해 편집 시간을 크게 줄입니다.
앱 미리보기
무엇을 할 수 있나요
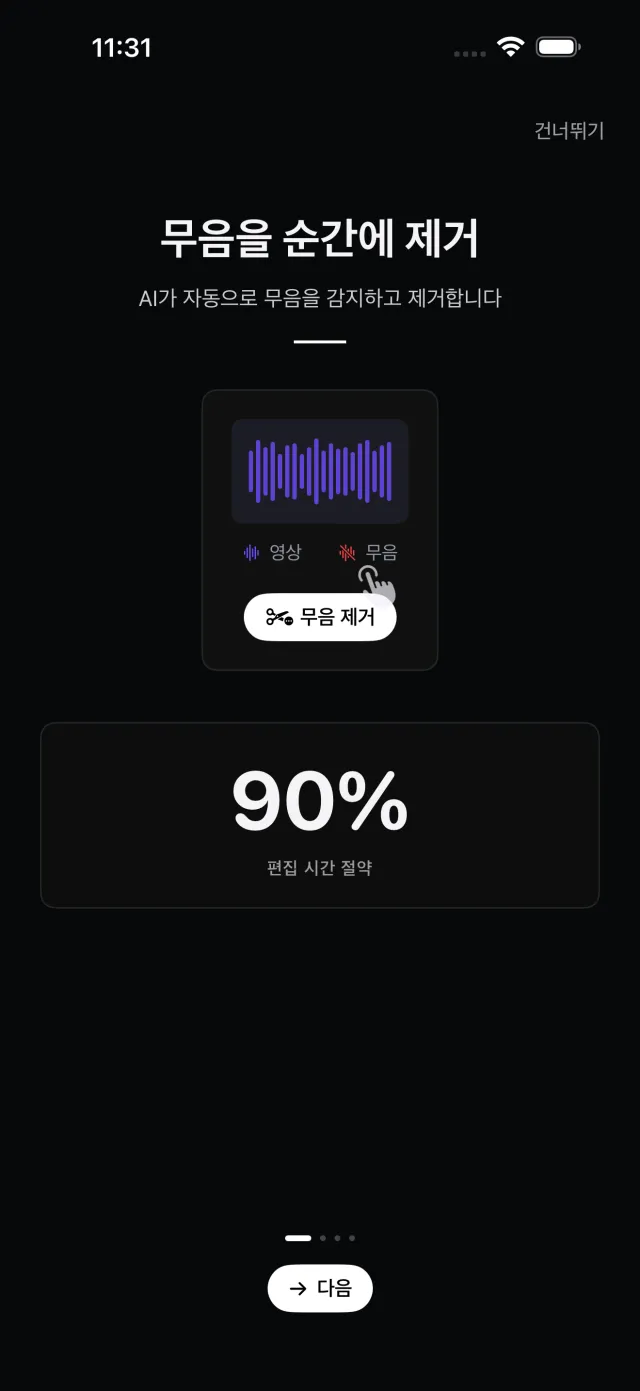
무음 구간 자동 감지·제거
AVAssetReader로 16-bit PCM(모노 44.1kHz)을 추출하고, 50ms 윈도우마다 Accelerate의 vDSP_rmsqv로 RMS를 계산합니다. 임계값(기본 -40dB)을 선형 진폭으로 환산해 그 이하인 연속 윈도우를 최소 길이(기본 0.5초) 기준으로 병합해 무음 구간을 산출하며, 임계값·최소 길이를 슬라이더로 조절해 미리보기할 수 있습니다.
필러 워드 단어 단위 감지
Speech 프레임워크의 SFSpeechURLRecognitionRequest로 영상을 인식하고(가능 기기에서는 requiresOnDeviceRecognition으로 온디바이스 처리), bestTranscription의 단어 세그먼트 타임스탬프와 한·영 필러 패턴 집합('음·어·아', um·uh·ah 등 망설임 / '그·뭐·약간', like·you know·basically 등 담화 표지)을 매칭해 군더더기 말을 단어 단위로 찾아 한 번에 잘라냅니다.
오디오 에너지 하이라이트 추천
vDSP로 오디오 에너지 엔벨로프를 계산하고, NaturalLanguage의 NLTagger로 자막 텍스트의 명사·고유명사 비율을 점수화해 결합합니다. 에너지가 높고 내용 밀도가 높은 구간을 목표 길이(기본 3~15초)에 맞춰 숏폼 클립 후보로 자동 제안합니다.
자동 자막·단어 단위 애니메이션·이중언어 자막
Speech 프레임워크로 음성을 자막으로 변환하고, TranscriptWord 타이밍에 맞춘 CABasicAnimation으로 karaokeHighlight·scalePop·wordReveal·bouncyEmphasis 등 단어 단위 캡션 효과를 렌더링합니다. 번역이 있는 자막은 DualSubtitleOverlayBuilder가 원문+번역(EN+KR)을 CALayer로 위아래로 쌓아 이중언어 자막을 만듭니다.
Auto Reframe 스마트 크롭
AutoReframeDetector actor가 영상에서 최대 40프레임을 샘플링해 Vision의 VNDetectFaceRectanglesRequest로 얼굴을 찾고, 실패하면 VNGenerateObjectnessBasedSaliencyImageRequest의 saliency로 폴백합니다. 프레임별 결과의 평균 바운딩 박스를 구해, 세로(9:16) 등 다른 화면비로 내보낼 때 ReframingTransformBuilder가 피사체를 중심에 맞춰 자동 크롭합니다.
플랫폼 프리셋 내보내기·FCPXML
YouTube Shorts·TikTok·Instagram Reels·YouTube·정사각 프리셋이 화면비(9:16·16:9·1:1)·권장 화질(1080p·4K)·최대 길이를 원터치로 맞추고, 길이 초과 시 경고를 표시합니다. FCPXMLExporter actor는 편집 타임라인(컷·속도 구간)을 Final Cut Pro XML로 직렬화해 외부 편집 툴과 연동합니다.
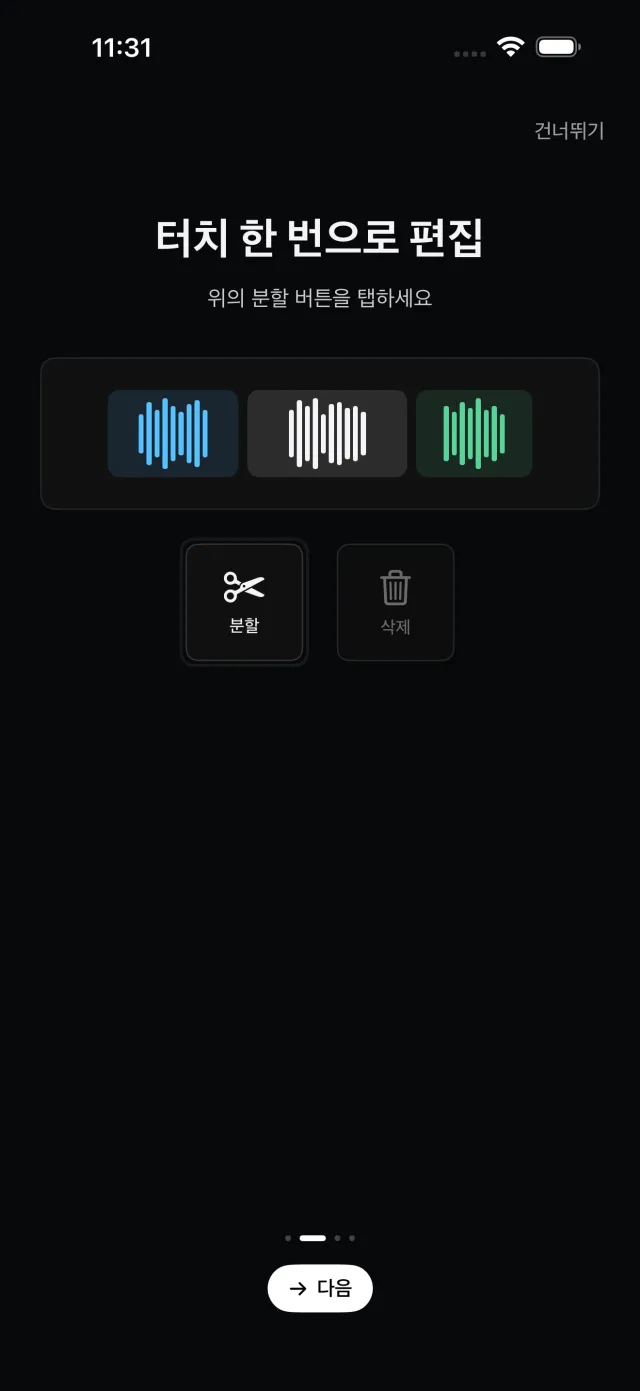
모자이크·크로마키 등 타임라인 도구
영역 모자이크는 Core Image의 CIPixellate/CIGaussianBlur로 구간별로 처리하고, 크로마키는 64³ CIColorCube LUT를 직접 생성해 HSV hue 거리와 채도로 특정 색을 premultiplied alpha로 투명화합니다. 그 외 구간 속도 조절, 전환 효과, PIP, 텍스트 오버레이, 배경 오디오 등을 UseCase 단위로 제공합니다.
온디바이스 합성·내보내기 파이프라인
VideoExporter actor가 AVMutableComposition으로 컷·속도·트랙을 조립하고, 필터·리프레임이 필요하면 CIFilter 기반 AVMutableVideoComposition을, 단순 트랜스폼이면 layerInstruction 기반 합성을 선택해 AVAssetExportSession으로 내보냅니다. 모든 과정이 기기 내에서 진행률 콜백과 함께 동작합니다.
어떻게 만들었나요
Language
UI
Media Composition
Image / Rendering
Audio / DSP
On-device AI
Interop
Data & Commerce
Domain / Data / Features / Core 레이어로 나눈 Clean Architecture 기반 iOS 앱으로, 무거운 미디어·음성·비전 처리를 10개의 actor로 격리하고 모든 처리를 온디바이스로 수행합니다.
- 1
Domain·Data·Features·Core로 분리한 Clean Architecture: Domain은 편집 UseCase(속도·전환·필터·텍스트·배경오디오·종횡비·Undo/Redo)와 Repository 프로토콜을, Data는 SwiftData·파일시스템 구현을 담당해 비즈니스 로직과 데이터 접근을 분리.
- 2
Swift 6 complete strict concurrency 환경에서 SilenceDetector·AudioAnalyzer·AutoReframeDetector·FillerWordDetector·HighlightDetector·SpeechRecognitionService·VideoExporter·FCPXMLExporter·VideoThumbnailGenerator·TranscriptGenerator 등 10개 처리기를 actor로 구현해 동시성 안전성을 컴파일 타임에 보장.
- 3
actor 경계 안에서 AVURLAsset을 생성해 비-Sendable 타입을 격리: AutoReframeDetector는 URL을 받아 내부에서 asset과 이미지 제너레이터를 만들고, withCheckedContinuation으로 프레임 캡처와 Vision 요청을 async로 안전하게 연결.
- 4
완전 온디바이스 처리: 음성 인식·오디오 DSP·영상 합성·얼굴/saliency 인식이 모두 기기 내에서 동작해 서버 업로드 없이 프라이버시 보장.
- 5
오디오 분석 파이프라인: AVAssetReader로 16-bit PCM을 추출하고 vDSP로 RMS/에너지 엔벨로프를 계산해 무음·필러·하이라이트 구간을 진행률 콜백과 함께 산출하며, NLTagger로 텍스트 밀도를 결합.
- 6
내보내기 합성 분기: VideoExporter가 AVMutableComposition으로 타임라인을 조립한 뒤, 필터·리프레임이 있으면 CIFilter 기반 AVMutableVideoComposition을, 없으면 layerInstruction 트랜스폼 합성을 선택해 AVAssetExportSession으로 렌더링.
- 7
MVVM 기능 구성과 영속화: 8개의 화면별 ViewModel과 @Observable 상태, 프로젝트/편집 상태는 SwiftData @Model과 Repository로 저장, 구독은 StoreKit 2의 Product.products·Transaction.currentEntitlements·Transaction.updates 리스너로 처리.
328
테스트
151
Swift 파일
10
처리기 actor
iOS 17
최소 지원 OS